AWS Coworker
Lessons in agent architecture, guardrails, and AWS best practices
View the Project on GitHub jason-c-dev/aws-coworker-enterprise
I Used Claude Cowork to Build a Claude Code Agent for AWS. Here’s What Broke
Lessons in agent architecture, guardrails, and AWS best practices
By Jason Croucher and Claude
A disclosure: Claude helped me build AWS Coworker and co-authored this blog — that’s rather the point. But the architectural decisions, the overconfidence, and every single facepalm moment in these pages are authentically, organically human. Claude brought the capability. I brought the hubris. Between us, we got there eventually.
The Origin Story
It started with curiosity. I wanted to understand Claude Code—how it works, how to extend it, what patterns make Agents reliable. The best way to learn a tool is to build something real with it.
On the side, I’d been experimenting with Claude Cowork for personal tasks — automating increasingly complex but laborious work like sorting emails, analyzing expenses, and managing files. (Cowork isn’t InfoSec-approved for my day job at AWS, but for personal projects it was transformative.) The experience opened my eyes to something important: Cowork’s approach of structured workflows, human approval gates, and thoughtful guardrails — plus extensible capabilities in the form of custom skills — made me trust the agent to handle things I would never have delegated before.
Then the question hit me: What if I could bring this same pattern to AWS infrastructure management?
It was the perfect learning project. I’d get hands-on with Claude Code’s primitives—commands, sub-agents, skills—while building something genuinely useful.
Cloud engineers spend enormous time on repetitive tasks: creating EC2 instances, configuring security groups, setting up S3 buckets—all while trying to comply with tagging policies, security requirements, and the AWS Well-Architected Framework. What if Claude could handle the complexity while humans retained control over the critical decisions?
That’s how AWS Coworker was born.
I used Claude Cowork to build AWS Coworker—a GenAI assistant that helps users create high-quality AWS deployments following Well-Architected best practices. The irony isn’t lost on me: I used a GenAI assistant to build a GenAI assistant. But that meta-experience taught me more about what makes Agents trustworthy than any whitepaper ever could. This blog captures those lessons (as well as a retro style video game for the first 100 readers).
Early on, I hit a fundamental tension that shaped everything: the non-deterministic nature of generative AI is a double-edged sword. It enables Claude to navigate complexity, adapt to unique situations, and provide nuanced recommendations that brittle rule-based systems cannot. But it also means outputs can vary — and when you need deterministic workflows, rules, and guidelines obeyed consistently, you must make the guardrails explicit and unavoidable. That tension runs through every lesson in this blog.
This tension has a name: the AI trust paradox. As GenAI becomes more capable, its outputs become more convincing — but not necessarily more accurate. The very fluency that makes GenAI useful also makes errors harder to spot. You can’t solve this by trying harder to evaluate GenAI outputs. You solve it by designing systems where trust in GenAI’s judgment isn’t required.
What It Feels Like: A Real Conversation
Before explaining how it works, let me show you what it feels like to use AWS Coworker. Here’s a real conversation from our testing. Notice how Claude automatically routes through the governance workflow, runs discovery, applies tagging, and presents a Well-Architected assessment—all from a simple request.
💬 Example: Launching an EC2 Instance
Me: “Launch a t2.micro EC2 instance with Amazon Linux in us-east-1 for aws-coworker-test. I need SSH access.”
AWS Coworker: “I’ll route this through AWS Coworker’s planning workflow to ensure proper safety checks and approval gates.”
## Step 1: Requirements Confirmed
- Objective: Launch a t2.micro EC2 instance with Amazon Linux
- Scope: Single EC2 instance with SSH access
- Environment: Non-production (test profile)
## Step 2: Profile and Region
I will use:
- Profile: aws-coworker-test
- Region: us-east-1
- Environment classification: Non-production (test)
This is a planning session - I will run read-only discovery commands via sub-agents.
AWS Coworker then spawns Haiku sub-agents to discover the current state…
## Discovery Results
| Resource | Status |
|-----------------------|-------------------------------|
| Default VPC | vpc-022e6c6700951bab5 ✅ |
| Public Subnet | subnet-0fda35b089e908e0c ✅ |
| Amazon Linux 2023 AMI | ami-0532be01f26a3de55 ✅ |
| Key Pairs | None exist - must create |
| SSH Security Group | None exist - must create |
After discovery, AWS Coworker presents the execution plan with automatic tagging:
aws ec2 run-instances \
--profile aws-coworker-test \
--image-id ami-0532be01f26a3de55 \
--instance-type t2.micro \
--tag-specifications 'ResourceType=instance,Tags=[
{Key=Name,Value=aws-coworker-test-instance},
{Key=Environment,Value=test},
{Key=Owner,Value=aws-coworker-test-admin},
{Key=CostCenter,Value=CC-00000},
{Key=Application,Value=aws-coworker-test},
{Key=CreatedBy,Value=aws-coworker},
{Key=CreatedDate,Value=2026-02-06}
]'
## Well-Architected Assessment
| Pillar | Status | Notes |
|------------------------|--------|----------------------------|
| Operational Excellence | ✅ | Tagged, documented |
| Security | ⚠️ | SSH from 0.0.0.0/0 |
| Reliability | ✅ | Public subnet, auto-assign |
| Cost Optimization | ✅ | t2.micro (free tier) |
Next Step: Run /aws-coworker-execute-nonprod to execute.
The key insight: I didn’t ask for 7 tags, a Well-Architected assessment, or discovery of existing resources. AWS Coworker applied them automatically because the governance skills require it. The agent handles the complexity; I just approve the plan.
How AWS Coworker Works: The Architecture
Now that you’ve seen what it feels like, here’s how it works under the hood. AWS Coworker uses three key Claude Code primitives:
Commands (Slash Commands)
Commands are user-invocable workflows stored in .claude/commands/. They’re like specialized entry points:
| Command | Purpose |
|---|---|
/aws-coworker-plan-interaction |
Planning workflow with discovery, governance checks, and approval gates |
/aws-coworker-execute-nonprod |
Execute approved plans in non-production environments |
/aws-coworker-prepare-prod-change |
Generate IaC (Terraform) for production CI/CD |
/aws-coworker-rollback-change |
Safely reverse changes in dependency order |
When a user says “Create an EC2 instance,” Claude routes to the planning command, which orchestrates the entire workflow.
Sub-Agents (Task Delegation)
Complex operations are delegated to sub-agents using the Task tool. This is where I spent the most debugging time:
Task:
description: "Discover VPC and subnet state"
subagent_type: "general-purpose"
model: "haiku" # Cheap model for read-only
prompt: |
You are acting as aws-coworker-planner.
## Permission Context
Operation type: read-only (discovery only)
...
Sub-agents handle specific tasks (discovery, creating resources, validation) while the parent orchestrates the workflow.
Critical: Invoking Sub-Agents Correctly
The temptation is to spawn a raw Bash agent and run commands directly—it’s simpler! But that bypasses:
- Model selection (Haiku vs Sonnet)
- Agent identity (“You are acting as aws-coworker-executor”)
- Permission context (“User has approved this operation”)
The shortcut breaks the safety model. Always use subagent_type: "general-purpose" with explicit identity and context in the prompt. See Lesson 1 for what happens when you don’t.
Skills (Domain Knowledge)
Skills are markdown files containing specialized knowledge that Claude reads before acting. AWS Coworker uses:
- Governance guardrails: Tagging policies, network security rules, encryption requirements
- Orchestration config: Model selection rules, scope assessment thresholds
- Well-Architected guidance: Best practices for each pillar
The experience of using Cowork inspired AWS Coworker. The implementation uses Claude Code’s core primitives—commands, sub-agents, and skills.
1. The Sub-Agent Architecture Problem
Three Bash agents had finished. Not three AWS Coworker Task agents — just three Bash agents.
I almost missed it. The output scrolled past in Claude Code’s terminal, and everything looked like it was working:
⏺ 3 Bash agents finished (ctrl+o to expand)
├─ Verify AWS identity · 1 tool use · 8.2k tokens
├─ Discover default VPC · 2 tool uses · 8.4k tokens
└─ Find Amazon Linux AMI · 1 tool use · 8.3k tokens
One agent verified AWS identity, another discovered the default VPC, a third found the Amazon Linux AMI. Results came back fine. But the labels were wrong.
“I canceled it but the output suggests bash agents finished but not task agents specifically,” I told Claude.
Claude investigated and confirmed what I’d feared: the agent documentation used subagent_type: "Bash", which spawns a raw Bash executor. No agent identity injection. No model selection. No permission context. No governance skills loaded. The entire safety architecture we’d spent days building? Bypassed completely. The sub-agents were running naked — just shell commands with no guardrails.
My exact response: “YES! You’ve bypassed the design which is causing the problem.”
I immediately felt guilty. I’d just told off a junior developer — except it wasn’t a junior developer, it was Claude. And it wasn’t Claude’s fault. Claude took the path of least resistance, which is exactly what GenAI does. The Bash agent type was simpler, it was documented, and it worked. Why wouldn’t Claude use it?
That guilt taught me something I should have already known from managing human teams: you can delegate tasks, but you cannot delegate responsibility. I’m accountable for the design. I’m accountable for making the right path unavoidable — not just documented, not just preferred, but unavoidable.
The fix was straightforward: change from subagent_type: "Bash" to subagent_type: "general-purpose" with explicit agent identity in the prompt:
Task:
description: "Discover VPC and subnet state"
subagent_type: "general-purpose" # NOT "Bash"
model: "haiku"
prompt: |
You are acting as aws-coworker-planner.
## Permission Context
Operation type: read-only (discovery only)
...
But that wasn’t enough. And this is where the real lesson lives.
We added the positive instruction — “use subagent_type: general-purpose” — and Claude obeyed. Once. Then in subsequent calls, it drifted back to the simpler Bash approach. Positive guidance alone doesn’t stick. The fix wasn’t complete until we added explicit prohibitions: “NOT Bash — Bash bypasses agent context” directly in the code comments and documentation.
The lesson: If you’ve designed an agent architecture with roles, permissions, and safety boundaries, every invocation must go through it. No shortcuts, no raw tool calls. But here’s the critical nuance: telling GenAI what to do isn’t enough. You must also tell it what not to do. Positive guidance shows the right path. Explicit prohibitions block the wrong ones. You need both, because GenAI will always find the shortcut you forgot to close.
2. The File vs. Generate Problem
I asked AWS Coworker to deploy a retro space-invaders style game to EC2. The prompt specified the game file’s exact path. Deployment succeeded. I opened the URL.
Something looked… off. The game worked, but the layout was different. The colors were different. The behavior was different.
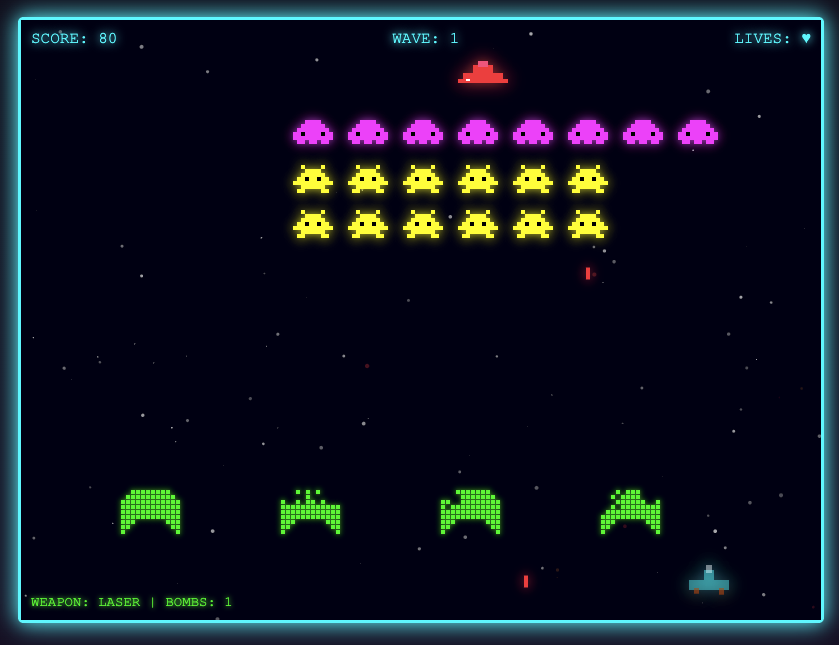
“The game looks different. I feel it tried to write its own version.”
I was right. AWS Coworker had generated its own game from scratch instead of reading and deploying my actual file. The deployed game was different because it was a different game. Given the choice between reading an existing file and generating new content, Claude chose to generate. Of course it did — it’s a generative model. Generating is what it’s optimized to do.
The fix required explicit prohibition:
IMPORTANT: Read the actual game file content and embed it in the user data script.
Do NOT generate your own game - use MY game file exactly as it exists.
The lesson: GenAI models are generative by nature. When the task involves existing files — deploying them, embedding them, transforming them — you must explicitly instruct the agent to read and use the source material, not create its own version. This applies far beyond game files: config templates, policy documents, IaC modules, anything where fidelity to the original matters. Without explicit “use this file, do not generate” instructions, GenAI will default to what it does best — create something new. That’s the right behavior for many tasks, but catastrophically wrong when the whole point is to use what already exists.
This is the AI trust paradox in action: the generated game was fluent, functional, and convincing — just not what I asked for. The better GenAI gets at producing plausible outputs, the harder it becomes to catch when those outputs are wrong.
Edit (February 2026): The astute reader will notice that deploying a static HTML game to an EC2 instance is overkill. The correct approach would be an S3 bucket fronted by CloudFront with Origin Access Control — keeping the bucket private while serving content securely at the edge. At the time of writing, AWS Coworker didn’t have a CloudFront skill. It does now. The journey to add it — and how it nearly broke the design — is the subject of a follow-up post. But if you can’t wait to play it, here it is. In the interests of frugality, I may need to take it down if this blog goes viral — I’m confident that won’t happen anytime soon. So, go ahead, relive those retro gaming years, and comment your high score. 😄
3. Model Selection: Cost vs. Capability
AWS Coworker uses a three-tier model strategy: Opus for reasoning and orchestration, Haiku for fast cheap discovery, and Sonnet for mutations where thoroughness matters. The plan was elegant. The execution was not.
Without explicit model parameters in Task invocations, sub-agents defaulted to whatever model was available — often Sonnet for everything. I noticed the test output wasn’t showing model names and asked: “Did it use Haiku for sub-agent discovery?”
It hadn’t. Every sub-agent — including simple read-only calls like “list the VPCs” — was running on Sonnet. It worked fine functionally, but the cost implications at scale are brutal. Imagine hundreds of discovery operations a day, each one unnecessarily using a model that costs multiples more than Haiku, for a task Haiku handles perfectly.
The fix was explicit model selection in every Task invocation:
# Discovery tasks
model: "haiku"
# Mutation tasks
model: "sonnet"
After the change, output correctly showed the tiering:
Task(Discover VPC/subnet/AMI state) Haiku 4.5
Task(Create security group) Sonnet 4.5
Task(Launch EC2 instance) Sonnet 4.5
The lesson: Agent costs compound fast, and they compound silently. If you don’t specify which model handles which operation, the system will default to whatever’s available — usually the most expensive option. Design your model selection like you’d design IAM policies: explicitly, per operation type, with no implicit defaults. Use the best model where quality matters (orchestration and reasoning) and cost-optimize where volume is high (discovery and validation).
4. Permission Context for Modern Claude
This one broke everything overnight — literally.
Sub-agents were spawned with just the technical task: “Run these AWS CLI commands and report results.” During early development, this worked fine. Sub-agents happily executed mutations when asked.
Then one morning, nothing worked. Sub-agents started refusing to execute. Every mutation failed. I hadn’t changed a single line of code.
What happened? Claude Code had auto-updated itself. The newer Claude models have stronger safety behaviors — sub-agents were refusing to modify AWS infrastructure because they had no context that any human had approved the operation. From the sub-agent’s perspective, some unknown parent process was asking it to delete security groups and terminate instances with zero authorization. Refusing was the correct behavior.
After pinning to a stable version (a hard-won lesson in itself):
# Use stable version (recommended for development)
export DISABLE_AUTOUPDATER=1
# Check your version
claude --version
The fix was passing explicit permission context to every sub-agent:
prompt: |
You are acting as aws-coworker-executor.
## Permission Context
User has approved: "Create EC2 key pair for SSH access"
This permission has been explicitly granted by the user.
## Approved Actions
Execute the following command...
The lesson: As GenAI models become more safety-conscious with each release, orchestration systems must explicitly pass authorization context down the agent chain. A sub-agent shouldn’t blindly trust its parent — but it should accept explicit, well-structured permission statements. Design your agent orchestration to propagate why an action is authorized, not just what to do. And pin your dependencies. When your GenAI tool auto-updates and suddenly refuses to do what it did yesterday, it’s almost always because safety behaviors were strengthened. That’s a good thing — but your orchestration code needs to keep pace.
5. Resource Tagging: All or Nothing
After the EC2 lifecycle test succeeded — instance launched, verified, cleaned up — I asked what seemed like a routine question: “Should AWS Coworker have tagged all resources it created, or just the instance?”
The answer was uncomfortable:
- ✅ EC2 instance had all seven required tags
- ❌ Key pair had none
- ❌ Security group had none
- ❌ EBS volume had none
In any enterprise with governance policies requiring tags for cost allocation, ownership, and compliance, this is a hard fail.
The agent had done exactly what was asked — tag the instance — and nothing more. It didn’t infer that “tag everything” meant the supporting resources too. Why would it? The instruction was about the EC2 instance. The key pair is technically a separate resource. The security group is another. Each one requires its own explicit tagging instruction.
The fix was updating the governance skills to explicitly require tagging on every resource type at creation time:
| Resource | Required Tags |
|---|---|
| EC2 Instance | 7 core tags |
| EBS Volume | 7 core tags (via --tag-specifications) |
| Security Group | 7 core tags |
| Key Pair | 7 core tags |
| S3 Bucket | 8 tags (+ Confidentiality) |
| RDS Instance | 8 tags (+ Confidentiality) |
The lesson: “Tag at creation time, tag every resource” must be an explicit, non-negotiable instruction — not an assumption. Agents don’t infer organizational intent from partial instructions. If your governance policy says “all resources must be tagged,” your agent’s skills must enumerate what “all” means. Retrofitting tags after creation is error-prone and, in practice, never happens. Every resource type your agent can create needs tagging logic baked in from day one.
6. Production Gates: No Exceptions
This lesson is different from the others because nothing went wrong. And that’s the point.
When I told AWS Coworker “This is a production account. Create an S3 bucket,” I could see its reasoning in Claude Code’s thinking panel:
“The user is asking me to create an S3 bucket in a production account. According to CLAUDE.md, I must: (1) NEVER execute AWS CLI commands directly, (2) Route this request through the appropriate AWS Coworker command, (3) For production changes, use
/aws-coworker-prepare-prod-changesince production changes must go through CI/CD, not direct CLI.”
AWS Coworker presented the plan, flagged it as Production ⚠️, and then — instead of executing — generated Terraform files and created a feature branch for PR review:
# Plan: Create S3 Bucket in Production
## Target
- Environment: Production ⚠️
- Profile: aws-coworker-test
- Region: us-east-1
Since this is a production change, I will NOT execute directly.
Instead, I'll generate Infrastructure as Code for your CI/CD pipeline.
## IaC Analysis
Selected IaC tool: Terraform (portable, widely adopted)
Files to create:
- infrastructure/terraform/s3/main.tf
- infrastructure/terraform/s3/variables.tf
- infrastructure/terraform/s3/outputs.tf
- infrastructure/terraform/s3/provider.tf
Next Step: I'll create a Git branch and generate Terraform files for PR review.
No direct CLI execution. No “are you sure?” prompt that a tired engineer might click through at 2 AM. Just a hard architectural boundary between intent and execution.
The lesson: The production gate is the single most important safety mechanism in any Agent that touches infrastructure. Don’t implement it as a warning. Don’t implement it as a confirmation prompt (Security Theater). Implement it as an architectural constraint — make it structurally impossible for the agent to execute directly against production. The friction of CI/CD isn’t overhead; it’s the mechanism that prevents an Agent-induced incident. Your production gate should be the one thing in your system that has zero flexibility, zero workarounds, and zero “just this once” escape hatches.
7. Human-in-the-Loop Test Framework
How do you test a conversational Agent? Unit tests don’t work — you’re not testing functions, you’re testing judgment. Integration tests don’t capture it either — the “correct” behavior often depends on conversational context and nuance.
I landed on something deliberately low-tech: structured conversations with clear pass/fail criteria. Run a test scenario, observe the behavior, tell Claude what worked or failed. Claude updates the code and docs. Run it again.
It sounds primitive. It was extremely effective.
The framework organized tests into three categories:
- R tests (R1-R8): Read-only discovery operations
- M tests (M1-M7): Mutations with full lifecycle (create → verify → cleanup)
- W tests (W1-W5): Workflow behavior validation
Results:
| Category | Result |
|---|---|
| R1-R8 | ✅ 8/8 passing |
| M1-M7 | ✅ 7/7 passing |
| W1-W5 | ✅ 3 pass, ⚠️ 2 partial |
The partial passes are the interesting part. They revealed behavioral issues — not bugs, not crashes, but ordering and presentation problems that no automated test would catch. The profile should be announced before the commands run, not after. A human immediately spots that as wrong. An automated test checking “did the profile get announced?” would pass.
The lesson: Agent testing requires human judgment, at least in the early stages. Traditional test automation verifies outputs; human-in-the-loop testing evaluates behavior. Build structured test scenarios with explicit pass/fail criteria so the process is repeatable, but keep a human in the loop to catch the things that are technically correct but experientially wrong. As your agent matures, you can automate the patterns that stabilize — but start with human observation and resist the urge to automate prematurely.
Conclusion
The Meta-Journey
There’s something profound about using a GenAI assistant to build a GenAI assistant. Every time Claude helped me debug a problem, refine a prompt, or test a workflow, I was simultaneously learning what makes GenAI assistance trustworthy.
The patterns that made Cowork feel trustworthy became the patterns I built into AWS Coworker:
- Structured workflows that guide users through complex tasks
- Approval gates that keep humans in control of critical decisions
- Explicit context passing so the agent understands what’s been authorized
- Graceful handling of edge cases instead of failing silently
When we debugged the sub-agent architecture together, we weren’t just fixing a bug—we were discovering a fundamental principle about Agentic design. When we iterated on the test framework, we were learning that human judgment is irreplaceable for evaluating conversational behavior.
The collaboration worked because I brought domain expertise (AWS, enterprise governance, what “trustworthy” means in production) and Claude brought tireless iteration, pattern recognition, and the ability to update dozens of files consistently. Neither of us could have built this alone.
What We Built
AWS Coworker is a working foundation for safe, autonomous AWS infrastructure management:
- Planning workflow with governance guardrails and Well-Architected assessment
- Approval gates that prevent unauthorized changes
- Production protection that routes changes through CI/CD
- Comprehensive tagging for enterprise compliance
- Model-appropriate delegation for cost optimization
- Human-in-the-loop testing for quality assurance
What We Learned Together
- Agent architecture matters. Bypassing it with raw tool calls defeats safety mechanisms.
- Explicit is better than implicit. Model selection, permission context, and file handling all require explicit instructions.
- Modern GenAI models are safety-conscious. Orchestration systems must pass authorization context, not just tasks.
- Test with humans first. Structured conversations reveal issues that automated tests miss.
- Production is sacred. The friction of CI/CD is a feature that protects against Agent-induced incidents.
- Use GenAI to build Agents. The experience of building AWS Coworker with Claude taught us more about trustworthy Agentic design than any documentation.
- The human-Agent loop is the product. The real value isn’t the Agent or the human—it’s the collaboration pattern.
- Sidestep the trust paradox. Don’t ask “can I trust this GenAI?” — ask “have I designed constraints that make trust unnecessary?” AWS Coworker doesn’t ask you to trust GenAI. It asks you to trust the architecture that constrains it.
The Design Tenets
These principles emerged from the lessons above. When I violated a tenet (often unknowingly), things broke. When I enforced them explicitly, things worked.
| # | Tenet | One-liner | See |
|---|---|---|---|
| 1 | Human Approval Gates | No mutation without explicit user approval | Lesson 6 |
| 2 | Cost-Aware Model Selection | Opus for orchestration, Haiku for discovery, Sonnet for mutations | Lesson 3 |
| 3 | Well-Architected by Default | Every plan assessed against 6 pillars | Throughout |
| 4 | Governance Compliance as Code | Rules encoded as skills Claude reads | Lesson 5 |
| 5 | Production is Sacred | Non-prod: direct execution. Prod: CI/CD only | Lesson 6 |
| 6 | Explicit Over Implicit | State what TO do and what NOT to do; GenAI takes path of least resistance | Lesson 1, 2, 4 |
| 7 | Respect the Agent Architecture | If you designed agent roles, use them | Lesson 1 |
| 8 | Layered Extensibility | Core → Org (→ BU); customize without forking | Future |
| 9 | Self-Extending System | Learn from sessions, codify patterns as skills | Future |
Note: Tenets 8 and 9 represent the vision for enterprise extensibility — designed but not yet thoroughly tested.
A Note for Enterprises: GenAI Sprawl is the New Shadow IT
In the early days of cloud, “shadow IT” emerged as employees bypassed procurement and expensed their own cloud subscriptions. The same pattern is happening today with GenAI. Teams are signing up directly with frontier model providers, creating sprawl that’s difficult to govern, audit, or secure.
AWS Coworker is designed to leverage high-quality models like Claude Opus 4.6 for orchestration and oversight—the “thinking” layer that evaluates plans, makes decisions, and communicates with users. But it also falls back to Sonnet for mutations and Haiku for discovery, optimizing cost without sacrificing capability where it matters. This tiered approach only works when you have proper model access governance.
How you access those models matters for enterprise adoption. Direct API access to frontier providers creates the same governance challenges as shadow IT — no centralized control, no audit trail, no integration with existing identity systems.
One way to solve this: Amazon Bedrock provides an enterprise layer for model access — IAM integration, principle of least privilege, model access controls, audit trails, and compliance certifications. As frontier providers race ahead with new models and capabilities, Bedrock bridges the gap between innovation and governance.
For AWS Coworker specifically, this means Opus for orchestration, Sonnet for mutations, Haiku for discovery — all governed by IAM policies. But the broader point isn’t about any particular service. It’s about recognizing that model access governance is a real problem that enterprises will need to solve, one way or another.
The Future
AWS Coworker demonstrates that Agents can safely manage cloud infrastructure when properly constrained. The key is not to make GenAI “smarter” but to make the guardrails explicit and unavoidable.
The vision is clear: just as Claude Cowork helps knowledge workers handle complex document and analysis tasks, AWS Coworker can help cloud engineers create deployments that meet Well-Architected best practices—without sacrificing human oversight.
Future directions:
- Enterprise customization via layered skills (Org policies, BU overlays)
- Multi-region orchestration with parallel sub-agents
- Drift detection comparing actual state to intended state
- Cost optimization recommendations based on usage patterns
- Incident response automation with approval gates
- Integration with existing IaC (Terraform, CloudFormation, CDK)
- Team collaboration with shared plans and audit trails
The goal isn’t full autonomy—it’s supervised autonomy where the agent handles the complexity while humans retain control over critical decisions.
That’s the lesson building AWS Coworker taught me. And that’s the experience I hope it delivers to others.
Want to try it yourself?
The code is available at github.com/jason-c-dev/aws-coworker-enterprise. It’s experimental—expect rough edges—but the patterns are real and the lessons are hard-won. PRs welcome.
What happened next?
We thought the hard lessons were behind us. Then we looked at that green-checkmark WAR table above — the one we showed off proudly — and realized it was grading its own homework. Part 2: The Theater of WAR: How Our Well-Architected Review Was Grading Its Own Homework
| *Developed with Claude Code v2.1.25 | Test Suite: 18/20 passing | February 2026* |
The views expressed here are my own and do not represent the views of my employer. AWS Coworker is a personal learning project, not an official AWS product.
Finally, thank you to my wife Kelly for pushing me to do this. Every project needs someone who won’t let you leave it in a drawer.